在 AI 项目中,大多时候开发者的关注点都集中在如何进行训练、如何调优模型、如何达到满意的识别率上面。但对于一个完整项目来说,通常是需求推动项目,同时,项目也最终要落到实际业务中来满足需求。
对于常用的 AI 训练和机器学习工具如 TensorFlow,它本身也提供了 AI Serving 工具TensorFlow Serving。利用此工具,可以将训练好的模型简单保存为模型文件,然后通过的脚本在 TensorFlow Serving 加载模型,输入待推理数据,得到推理结果。
但与拥有较固定计算周期和运行时长的 AI 训练不同,AI 推理的调用会随着业务的涨落而涨落,经常出现类似白天高、夜间低的现象。且在大规模高并发的节点需求情况下,常规的部署方案,明显无法满足此类需求,此时需要使用更专业的 AI 推理模型和扩缩容、负载均衡等技术完成预测推理。
UAI-Inference 采用类似 Serverless 的架构,通过请求调度算法、定制扩缩容策略,自动完成 AI 请求的负载均衡,实行节点动态扩容和回收,可提供数万的 AI 在线推理服务节点。
某AI在线推理一天内的请求访问情况
AI 推理(Inference)的在线执行有两大关键因素:一是通过 GPU/CPU 对数据进行快速决策,二是对访问请求的实时响应。下图为某一 AI 在线推理场景 24 小时内的资源使用情况,其中,横轴为时间、纵轴为用户资源请求量,橙色线现表示资源配置情况。

凌晨 00:00-8:00 点,用户基本处于睡眠状态,此刻的资源请求较少,闲置资源较多;8:00 以后,手机等设备使用量增多,推理访问请求逐渐上升;直至中午,设备访问达到高峰,请求量超过设定的资源量,系统纺问出现延迟;之后在线使用量降低,部分资源又将闲置……
可以看到,一天内不同的时间段,访问量会随着用户作息规律而出现相应的起伏,若是将资源配置设置过小,则会导致计算资源不足,系统吞吐量变低,致使访问延迟。但若投入过多的配置,又会产生大量的闲置资源,增加成本。
面向大规模的AI分布式在线推理设计与实现
UAI-Inference 整体架构
为了应对在线推理对实时扩缩容以及大规模节点的需求,UAI-Inference 在每一台虚拟机上都部署一个 AI 在线服务计算节点,以类似 Serverless 的架构,通过 SDK 工具包和 AI 在线服务 PaaS 平台,来加载训练模型并处理推理(Inference)请求。整体架构如下:
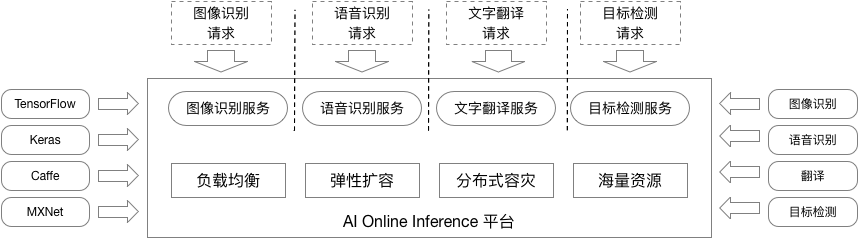
SDK 工具包:主要负责模型加载。包含接口代码框架、代码和数据打包模板以及第三方依赖库描述模板。用户根据 SDK 工具包内的代码框架编写接口代码,准备好相关代码和 AI 模型以及第三方库列表,然后通过打包工具将训练模型进行打包。
任务打包完毕后,系统自动将业务部署在 AI 在线推理 PaaS 平台上处理推理请求。这里,平台每个计算节点都是同构的,节点具有相等的计算能力,以保证系统的负载均衡能力。此外,动态扩缩容、分布式容灾等弹性可靠设计也是基于该平台实现。
在线推理实现原理
在实现上,系统主要采用 CPU/GPU 计算节点来提供推理任务的基础算力,通过 Docker 容器技术封装训练任务,内置 Django Server 来接受外部 HTTP 请求。下图展现了处理请求的简单原理与流程:
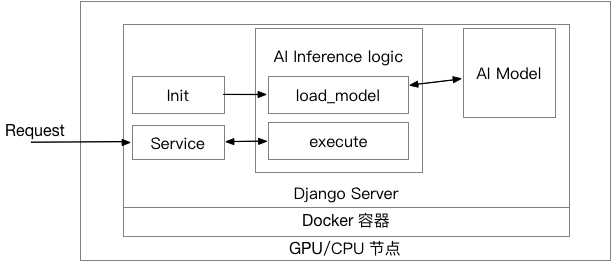
在初始化过程中(init),Django Server 会先根据 conf.json 加载 AI Inference 模块,然后调用该模块的 load_model 将 AI 模型加载到 Django HTTP 服务器中;在处理推理请求时,Django 服务器会接受外部的 HTTP 请求,然后再调用 execute 函数来执行推理任务并返回结果。
这里,采用容器技术的好处是可以将运行环境完全隔离,不同任务之间不会产生软件冲突,只要这些 AI 服务在平台节点上运行满足延时要求,就可进行 AI 在线推理服务部署。
功能特性
UAI-Inference 适用于常见的大规模 AI 在线服务场景,如图像识别、自然语言处理等等。整体而言,该系统具有以下功能特点:
面向 AI 开发:通过预制的 NVIDIA GPU 执行环境和容器镜像,UAI-Inference 提供基于 Docker 的 HTTP 在线服务基础镜像,支持 TensorFlow、Keras、Caffe、MXNet 多种 AI 框架,能快速 AI 算法的在线推理服务化。
海量计算资源:拥有十万核级别计算资源池,可以充分保障计算资源需求。且系统按照实际计算资源消耗收费,无需担心资源闲置浪费。
弹性伸缩、快速扩容:随着业务的高峰和低峰,系统自动调整计算资源配比,对计算集群进行横向扩展和回缩。
服务高可用:计算节点集群化,提供全系统容灾保障,无需担心单点错误。
用户隔离:通过 Docker 容器技术,将多用户存储、网络、计算资源隔离,具有安全可靠的特性。
简单易用:支持可视化业务管理和监控,操作简单。
在线推理的可靠性设计
因为推理请求是随着访问量的变化而变化的,因此,在线推理的可靠性设计,考虑以下几点:1)充足资源池,保证在高并发情况下,系统拥有足够的计算资源使请求访问正常;2)负载均衡:将请求合理的分配到各节点当中;3)请求调度算法:用于计算资源的实时调度;4)性能监控:查看用户访问状态,为系统扩缩容做参考;5)高可用部署:保证在单节点宕机时,系统能够正常运行。
负载均衡
UAI-Inference 为每个在线服务提供了自动负载均衡能力,当用户提交同构、独立的 AI 在线推理容器镜像时,平台会根据请求的负载创建多个计算节点,并使用负载均衡技术将请求转发到计算集群中。

如图所示,负载均衡主要包括网络层和转发层。网络层中,同一个交换机(IP)可以接多个后端节点,通过请求调度算法将请求分配到各个计算节点当中。调度算法可以采用Hashing、RR(Round Robin)、Shortest Expected Delay等,其中,Hashing 适用于长链接请求,Shortest Expected Delay 适用于短链接请求。目前,UAI-Inference 采用 RR 的方式在计算节点间调度请求。整个系统最底层是一个统一的资源池,用以保证充足的计算资源。
动态扩缩容
在实现扩容之前,需要通过监控了解各节点当前的在线推理状态,这里,主要是通过实时收集节点的负载(CPU、内存)、请求的 QPS 和延时信息,来制定动态的扩容和缩容策略。
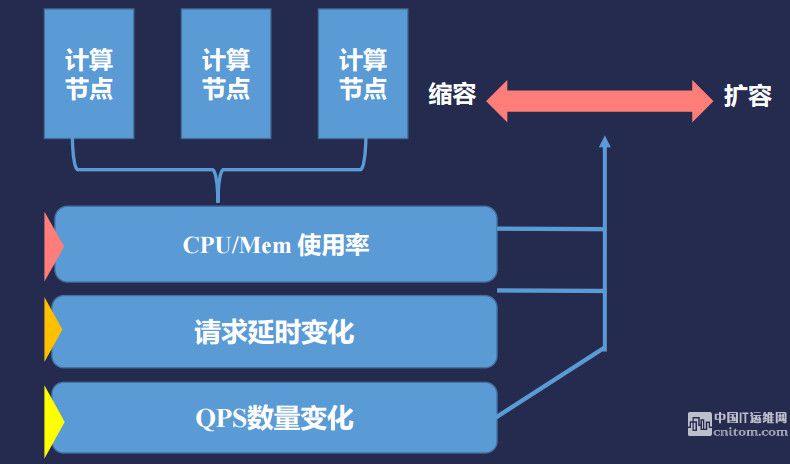
系统状态实时监控
此外,UAI-Inference 系统将 HTTP 请求、延时和 HTTP 返回码实时记录成日志,然后通过数据统计来在图形界面展示 HTTP 请求量、延时、成功率等信息。平台会实时收集所有计算节点的 stdout 数据,并录入日志系统,用户可以通过观察线上运行日志来了解线上运行状态,并根据监控信息自动选择扩容和缩容。
高可用
除了基本的扩缩容和负载均衡,我们也通过将计算节点集群化的方式,提供全系统容灾保障。如下图所示,系统会把整个服务切分成多个 set,部署在跨机房的某几个机架或者区域里面,当某一个机房或者 set 宕机时,其他地区的在线推理处理还在进行。这种方式的好处是当出现单点故障时,其他区域的计算节点能够保证整个在线推理请求的正常执行,避免因单节点故障导致的系统不可用。

总结
本文通过对 UAI-Inference 的实现原理、架构设计以及弹性扩缩容、负载均衡、高可用等可靠策略的介绍,讲解了大规模、高并发在线推理请求时,UCloud 的部分解决策略和方案。希望能够抛砖引玉,为其他开发者做AI在线推理部署时带来新的思路。
截止目前,UAI-Inference 提供了 CPU/GPU 数万节点的在线推理服务。未来,我们会兼顾高性能在线服务和高性价比的在线服务两个方向,同时提供针对 GPU 硬件和 CPU 硬件的优化技术,进一步提升在线服务的效率。同时也会着力于公有云和私有云的结合,后期将会推出私有云的在线推理服务。
作者 ·宋翔
UCloud 高级研发工程师。负责 UCloud AI 产品的研发和运营工作,曾先后于系统领域顶级会议 Eurosys、Usinex ATC 等发表论文,在系统体系架构方面具有丰富的经验。


