1. HDFS对底层的磁盘存储如何选择的?
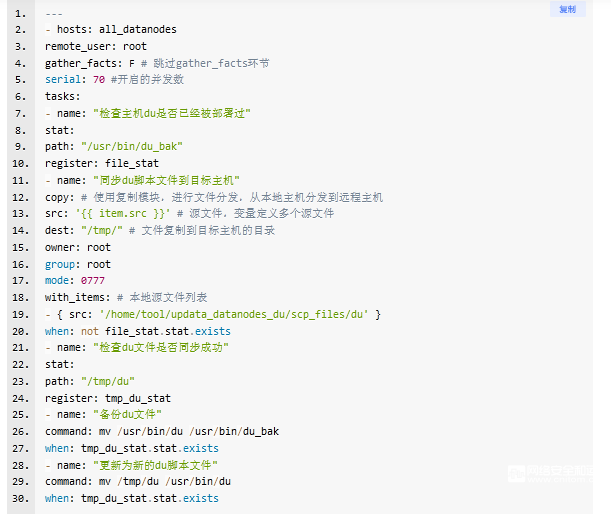
一个HDFS集群,会有很多个datanode节点,每个datanode节点会挂载很多块磁盘。HDFS在存储数据时如何动态负载均衡最优化地往每个datanode,每个磁盘上存储数据呢?
其实没啥,DataNode在运行过程中,为了计算DN的capacity使用量,实现数据存储的动态均衡,DN会对已配置的数据存储路径(dfs.datanode.data.dir)进行du -sk操作,以此获得capacity使用量汇报给NN中,然后NN就知道哪些DN有空间能被写数据进去,哪些是空间不足的。
为了保证数据使用量的近实时性,目前DN是以默认10分钟的间隔时间执行一次。假设按照一个DN节点12个数据目录对应12块盘的情况,就会有12个du操作在每个10分钟内都会执行一次。在datanode存储的数据使用率比较高的时候,会十分消耗性能。直接引发阻塞io,系统load直线增高。
这种问题在大规模的集群中是很常见的,下面是针对线上(hadoop2.6版本的)简易零时的优化手段。说明:此问题仅存在于低于hadoop2.8版本,高于此版本已经修复。
https://issues.apache.org/jira/browse/HADOOP-9884
如果碰到这种情况,升级不了集群版本,那么我们还有其他奇技淫巧吗?
2.通过修改HDFS代码实现优化
先回顾一下du,df的使用
du原理简述:
du命令全程disk usage,它的统计原理在于将目标路径下的当前没有被删除的文件进行大小累加,然后得出总使用量。这种计算方式在文件数量少时往往不会表现出什么问题。但是当目标路径目录多,文件多的时候,du会表现出明显的时间执行耗时。
df 原理简述:
df命令统计值通过文件系统获取的。df命令的弊端是它不能按照具体目录进行使用量的统计。df是按照所在磁盘级别进行统计的。换句话说,用df命令在属于同一块物理盘的子路径下执行df命令,获取的值会是完全一致的。比较遗憾,这种情况将无法支持DataNode多block pool共用一块盘的情况。
处理方式:使用 df 命令替换 du
捕获到datanode执行过程中调用的 du -sk 命令,替换为df -k 。
实现脚本如下:
##将原始的 du指令更换名称