日前,在AICC2018人工智能计算大会上,美国杜克大学终身副教授、美国自然科学基金委智能与可持续计算产学合作中心主任陈怡然先生做了关于《人工智能芯片设计中的挑战》主题演讲,引发广泛讨论。
以下为陈怡然教授演讲摘录:
刚才会议开始的时候王恩东院士讲我们有三次浪潮,这三次浪潮分别代表了不同算法的突破,我只经历了一次浪潮。这三次浪潮延续了70年的时间,从1940年到现在每次浪潮都伴随着新的算法模型的兴起,但是它不是孤立存在的,伴随着计算能力的不断提高。如果大家把眼光放到技术计算来看,计算技术的发展其实是一个持续发展的现象,过去五年如果看到GPU单板计算能力的提高,大概只提高了3-4倍,但模型参数总数目提高了几百上千倍。所以我们面临的调整你是要了解人工智能应用的硬件要求是什么,芯片要怎么去设计才能变得更有效,从而弥补摩尔定律本身的发展和参数上的增加所带来的差别。

冯诺伊曼体系有以下几个特点:存储和计算是分离的,控制单元可以把数据从内存调到计算单元,计算单元经过处理以后再传回到内存。过去有大量的科学计算的应用,非常成功。但是这种单线程在冯诺伊曼体系里受制于运行指令之间的数据依赖的影响,当你大规模运行的时候会发现性能会掉得非常厉害。从此我们就做到多核,多核又带来了一些新的问题,比如带宽或瓶颈的问题,片上计算能力不断提高,但是内存带宽又不断受限,往往不能达到最高的有效的计算。当然还有另外一个问题是功率密度的问题,我最近跟学生开了一个笑话,我上大学的时候攒机器,一个CPU100美元-200美元,现在还是这个价格甚至更便宜了,我当时在中关村买一个风扇只要几毛钱,现在好的要几十美元,很贵了,做CPU真的比做风扇赚得多。

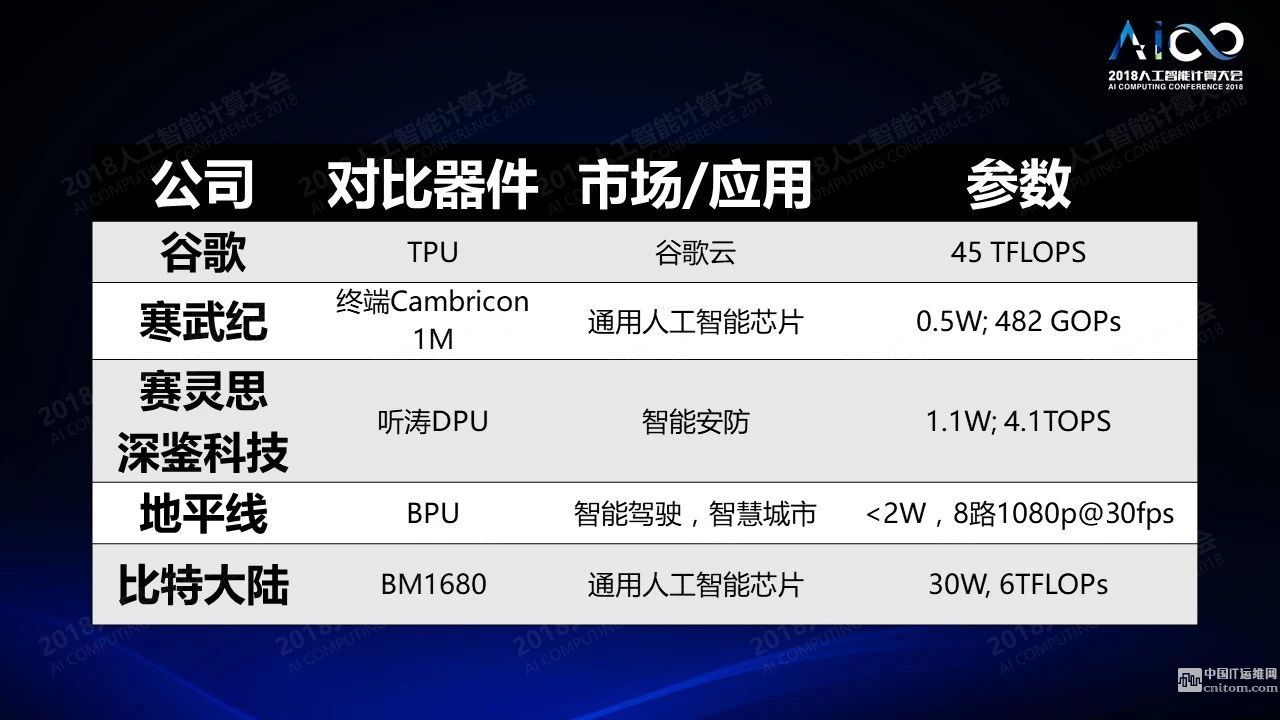
我们发现越来越多的应用需要更多新式的芯片进行处理,这种处理的要求是跟传统的CPU和GPU不太一样,虽然这些运算也可以用GPU来做加速。GPU本身是一个流式的处理器,它可以有效进行向量之间的运算,如果我们用n表示计算的能力,它把每个规模为n计算变为了1。从这个角度出发大家用FPGA进一步加速计算的过程,比如国内比较有名的深鉴科技用FPGA进行网络神经的加速设计,谷歌TPU通过脉冲阵列的形式加速神经网络的计算,国内另外一家公司寒武纪设置了专门的指令集,对于不同的向量与向量之间,向量与矩阵之间进行加速。要说明大家对于不同的架构的应用场景也基本是不一样的,这只是列了其中一些比较有代表性的例子,此外还有非常多。芯片设计的参数集中在计算性能,还有功耗,最终数据的吞吐量等等。所有这些参数都是我们关心的问题。

挑战1:大容量存储和高密度计算
我们的第一个挑战,大容量存储和高密度计算,当神经深度学习网络的复杂度越来越高的时候,我们会面临一个问题:你的参数越来越多,你该怎么办?大家常见的一个技术是做剪枝:神经网络里面有大量的冗余,这种冗余是可以被去除的,去除以后基本不会影响计算精度。比如简单的想法就是如果我知道有一个权重很小,对于输出结果没有太大影响,那就可以去掉。你在去除的过程中遇到这样一个问题:这样的权重在训练之后是随机的分布在整个向量空间里。当你把这个稀疏网络存在一个计算机存储系统的时候读取这个网络会带来大量的访问缺失。比如当你读取一个数据之后,下一个数据往往并不是计算所需要的,这就带来了存储器访存的缺失。

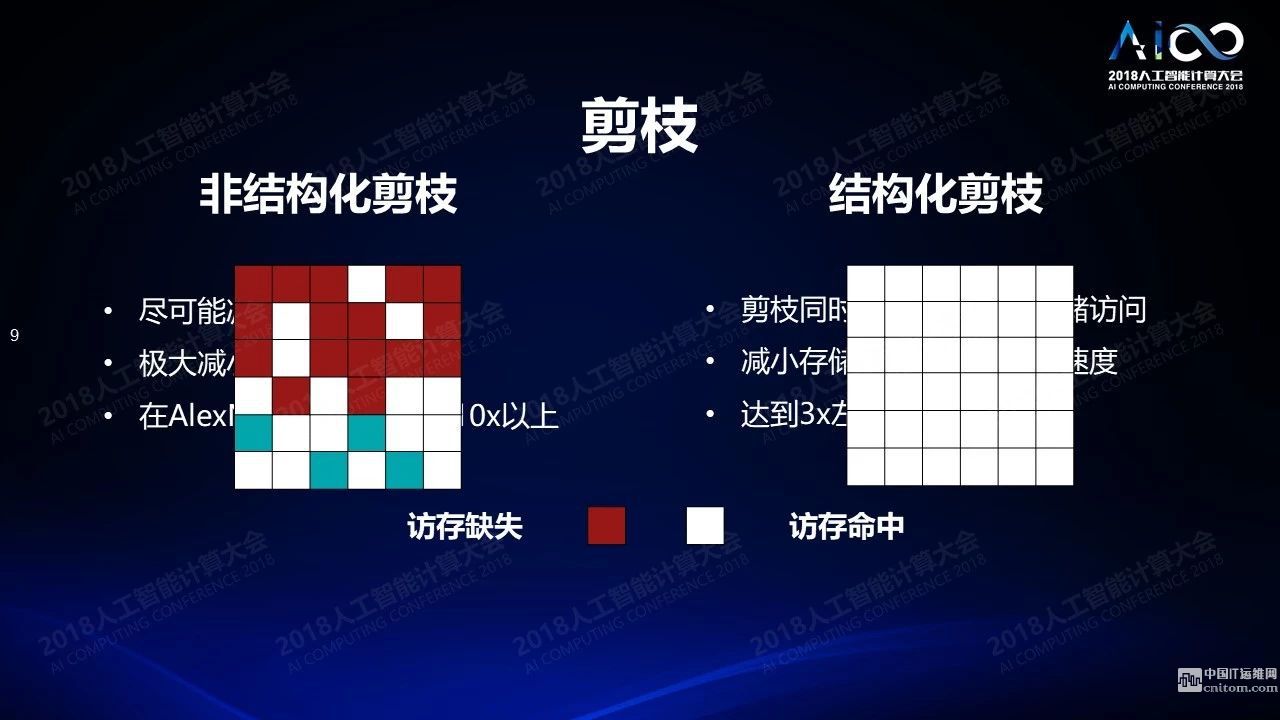
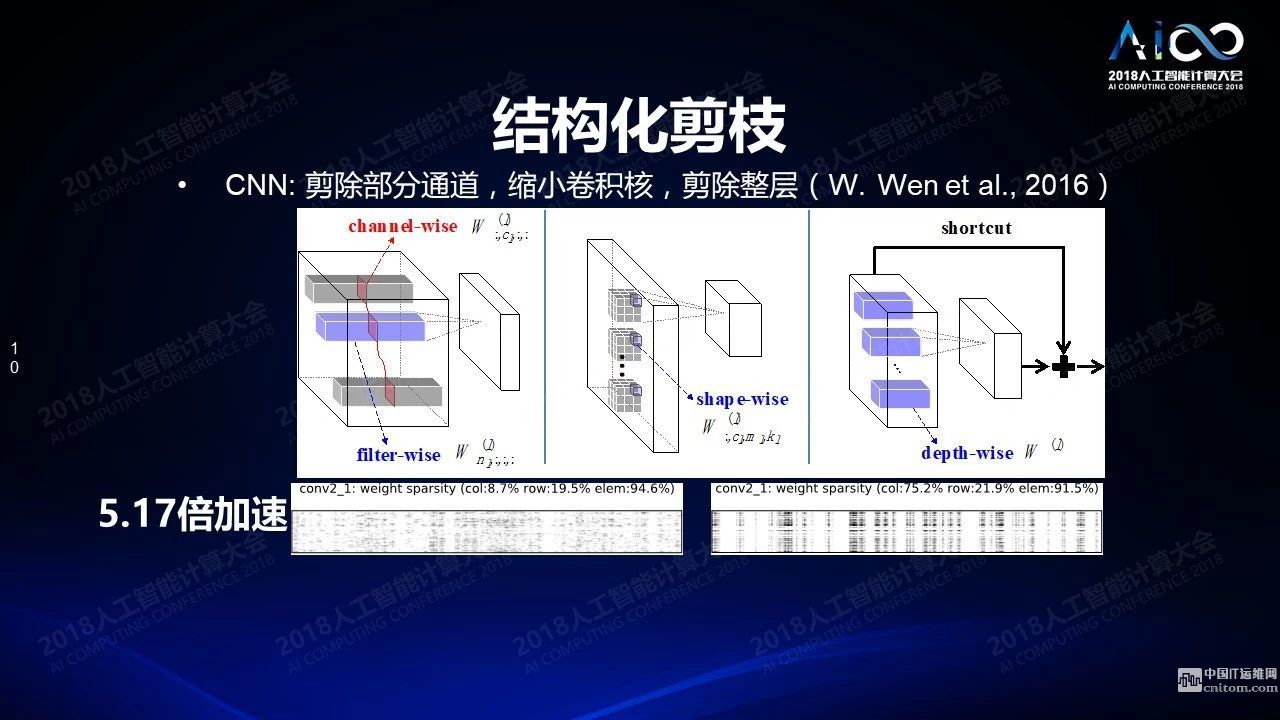
我们可以通过软件的方式解决这个问题,比如在数据结构上打补丁。这些在我看来并不是很聪明的办法,没有解决根本性的问题。根本性的解决方案是结构化的剪枝:当你在去掉这些权重的时候如果不是一个一个单独的随机的去掉而是一块一块的去掉,尽量介绍对它存储方式的影响。这个工作是我们2016年NIPS的一篇文章《结构稀疏化》,今年年初已经被英特尔的芯片系统支持了。结构稀疏化另外一个问题是什么样的层次下做到稀疏化,可以把通道所对应的权重整个去除掉,把卷积核对应的权重整个去除掉,甚至整层去除掉,最后都会带来结构稀疏化的结果。下面两张图左边是随机去除的结果,右边是结构去除的结果,左边和右边相比可以带来10倍的性能提升,这个工作是我们跟英特尔一块做的,他们后来把这个技术在产品里给支持了。
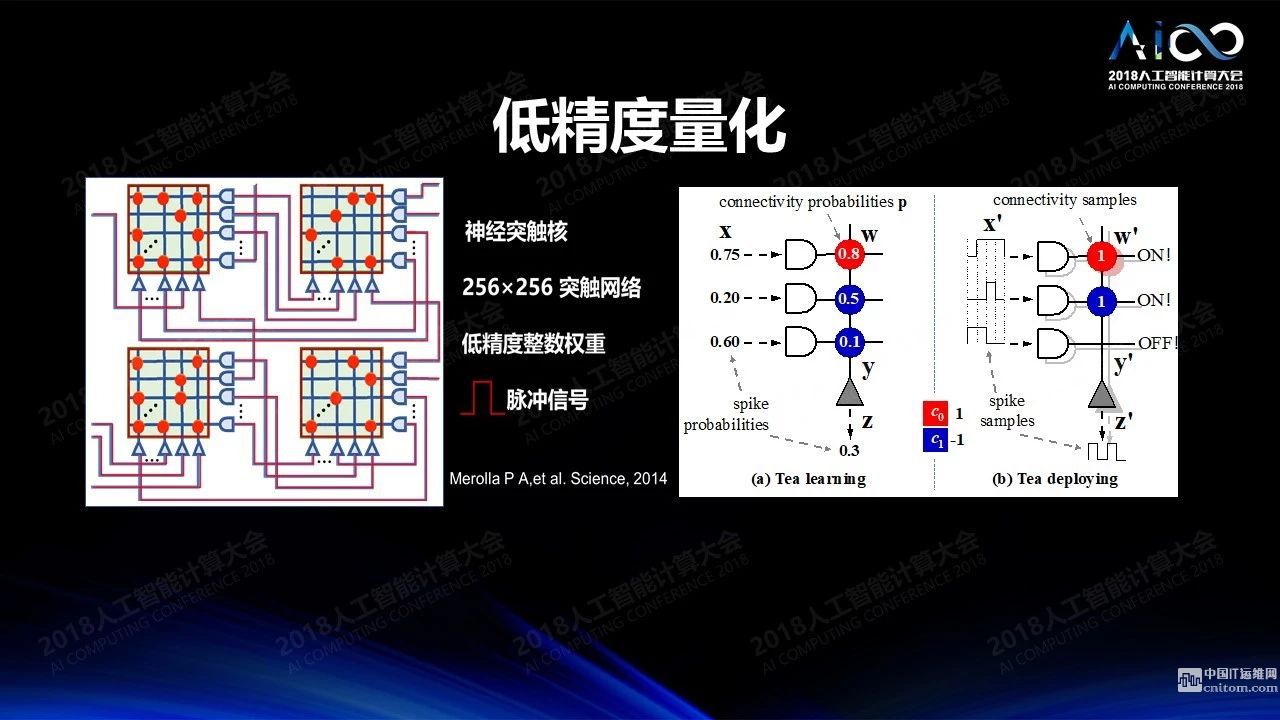
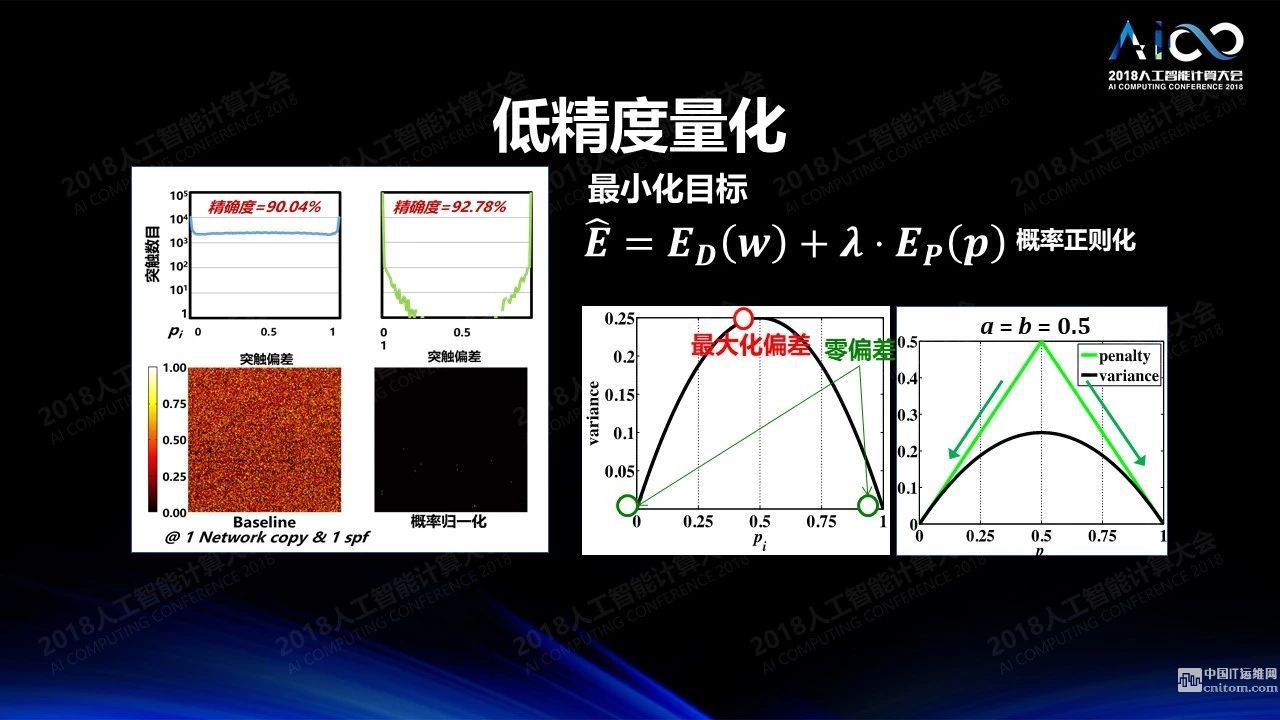
低精度:我们在训练的时候需要高精度,但做推理的时候不一定需要高精度,低精度的运算可以极大降低运算的开销,提升运算的效率,又不怎么降低计算的准确度。一个极端的例子是IBM的真北芯片,所有数据和权重都是通过三值来实现的,+1、-1和0,怎么仍然能达到比较高的精度呢?传统意义上采用了冗余的设计,比如输入为0.75,如果有四个脉冲的位置,有3个脉冲出现就表达0.75。如果权重是0.8,那么我们就保留5个神经网络的拷贝,其中相应的权重四个为1一个为0。这样的结果是非常浪费的,根本的解决方法不应该是通过冗余的方式来设计,应该通过训练得到一个简单的三值网络。我们来做一个小小的脑力体操,我们训练一个网络的时候究竟是把它按照一个高精度的网络来训练还是把它训练成所有的精度都尽可能靠近0和1,从而能够理想的写入只可以存三值的存储空间。答案当然是后者。如果我们能够把训练网络的时候就训练成一个三值网络,我们训练所得一定是把它写入到硬件系统之后的所得。所以我们在训练的时候对每个权重做处理,使得所有训练后的权重都向0和1靠拢,结果就会变得比较好。我们通过这种方式在IBM达到性能6-7倍的提升,我们所做的其实就是改掉一行程序。
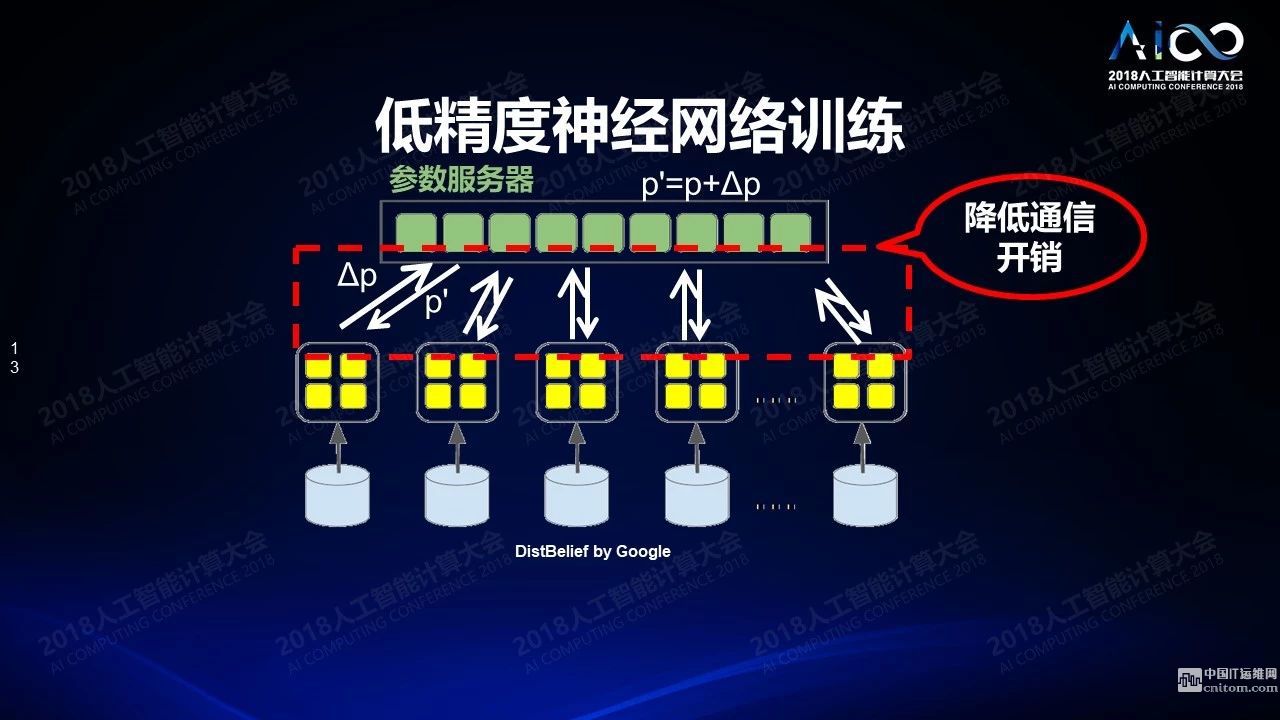
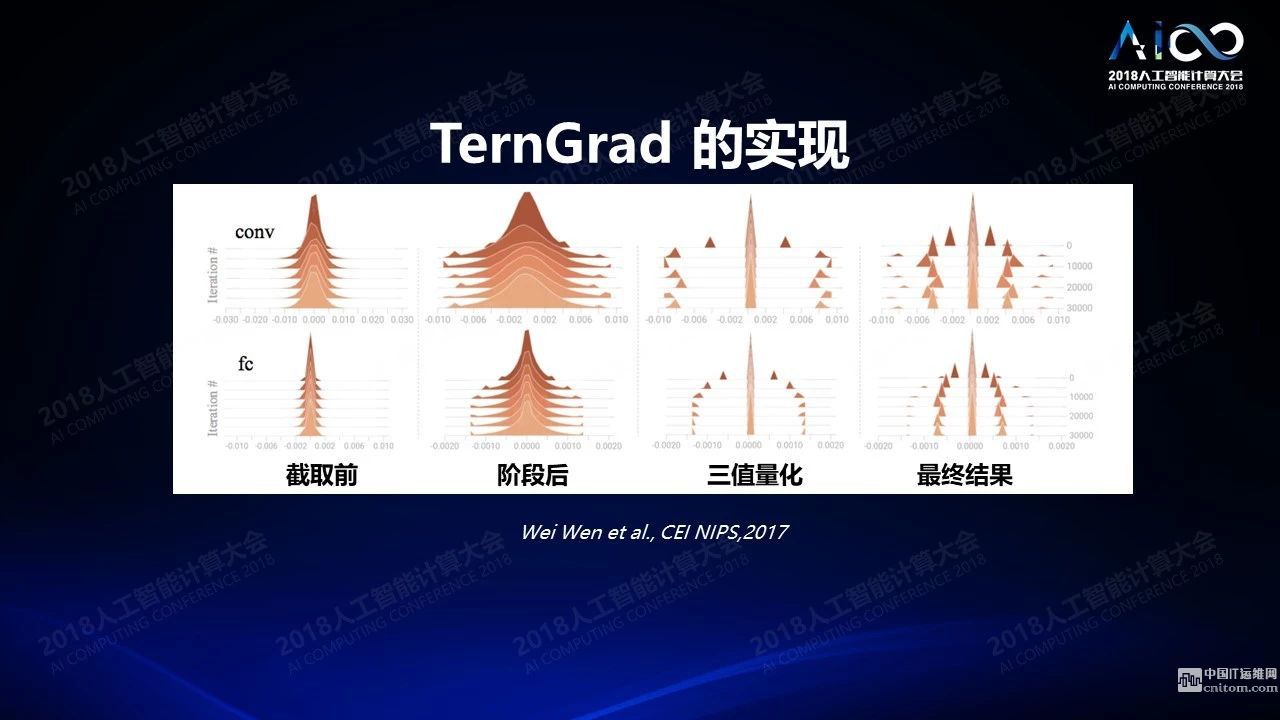
低精度神经网络训练在分布式系统上的应用通常使用参数服务器。我们有很多神经网络的拷贝,这些拷贝在每个节点上都会用不同的数据来训练,一段时间之后我们把训练的结果发送到参数服务器来同步,再把同步后的结果分发下去。但当系统特别大的时候就会遇到一个问题:它的规模不能持续扩大,因为大量的通信带宽都消耗在节点和参数服务器互之间的数据传输,我们怎么降低开销?当然如果用0、+1、-1来表示数据的话数据量就会变得非常少。但是这样的三值只能表示方向不表示数据大小。我们实际测试中发现其实所有数据传输,当数据足够大的情况下其实都满足于某一种分布。因此数据比较大的情况下只需要传大概2到3个值,剩下的只要传方向,就可以在另外一端把数据整个恢复出来,这样就完全不必要传我们的数据采样而只需要传分布就可以了,这样的结果是我们在128个节点的GPU集群上可以达到3倍左右的训练加速,性能精确度大概降低了不到2%。

挑战2:面临特定领域的架构设计
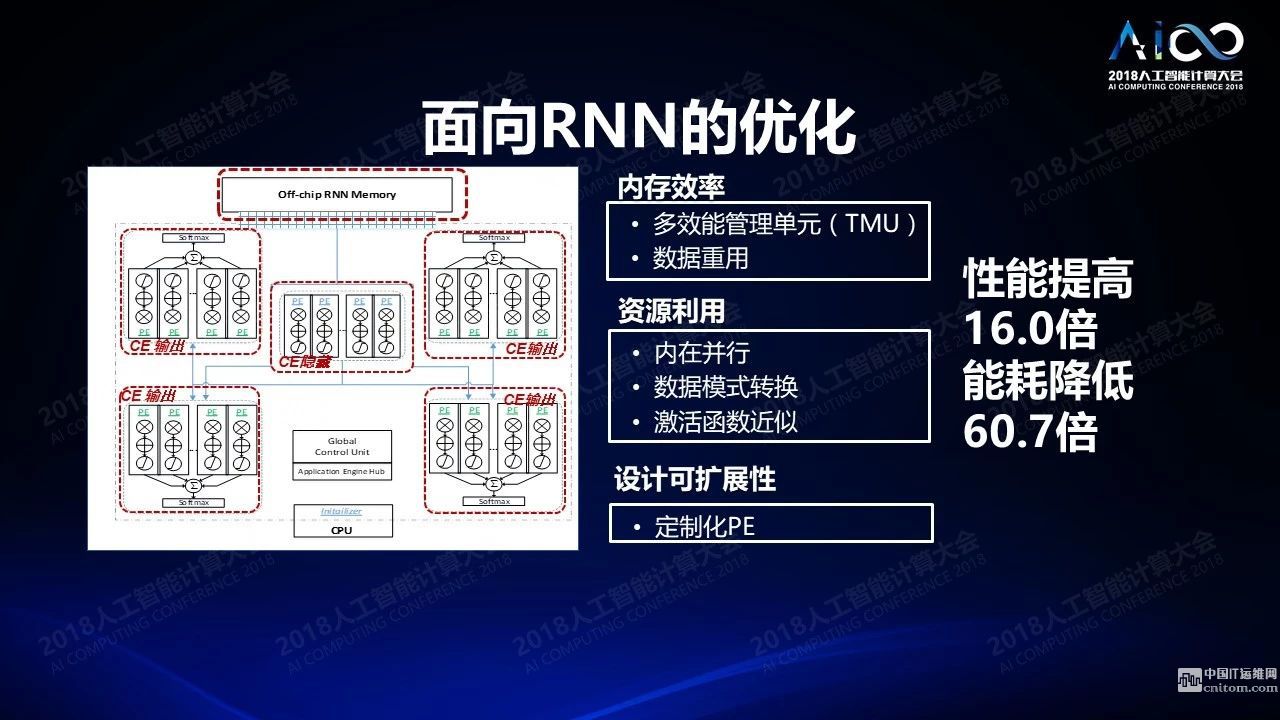
我们第二个挑战是面临特定领域的架构设计,因为我们的场景越来越丰富,而这些场景的计算需求是完全不一样的。比如我们从图像处理场景得到的知识,当我们面临语音应用的时候它能够重复使用的部分是非常有限的。所以我怎么样通过对于不同的场景的理解设置不同的硬件架构变得非常重要。举一个简单的例子,很多人用FPGA做图象处理,而图像处理不需要考虑时域上的信号传播。这在语音处理的时候是必不可少。所以在2015年的时候我们在FCCM,是FPGA领域的一个顶级会议上发布了关于RNN的优化。我们通过内存效率提升,激活函数的近似和提高基础单元设计的可扩展性,达到了相当于CPU性能16倍的提高,而功耗降低了60倍,这是比较典型的例子。

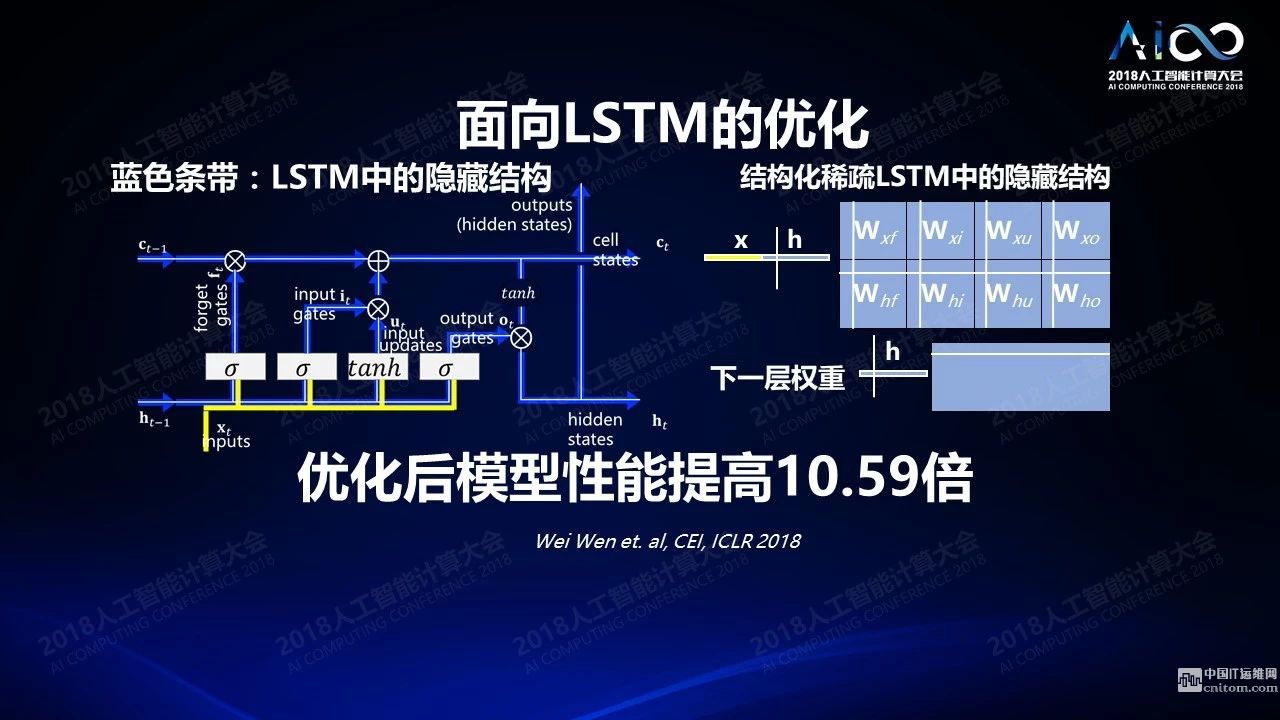
不仅如此,我们在算法上也可以做相应的转换,今年我们发布了一篇文章,在语音的LSTM的模型上我们直接结构稀疏化它的隐藏结构,这种隐藏结构的稀疏可以达到10倍性能的提升。即使在一些复杂的自然语言处理场景下我们也可以带来20-40%左右的性能提升,精确度做到了大概只有1%的损失。现在这个技术已经被某大公司直接用在了他们的硬件设计上。
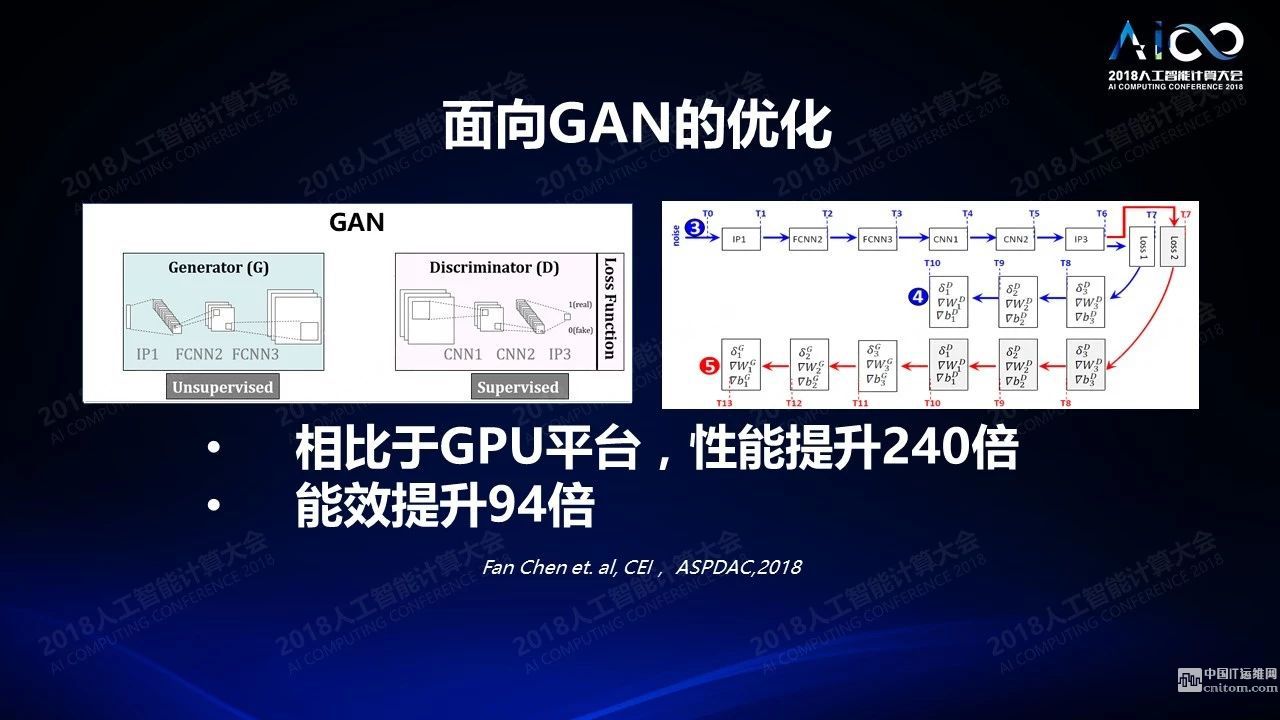
最近GAN比较热,它可以很有效的通过两个网络相互之间的学习来生成一些现实场景中不存在但是又真实可信的数据,GAN的应用在非监督学习上会有大量的应用和突破。我们最近有一篇文章在讲我们体系结构上也可以生成一种新的流水线,使得对于GAN的训练效率有很大的提高。
挑战3:“云-终端”平台特点不同
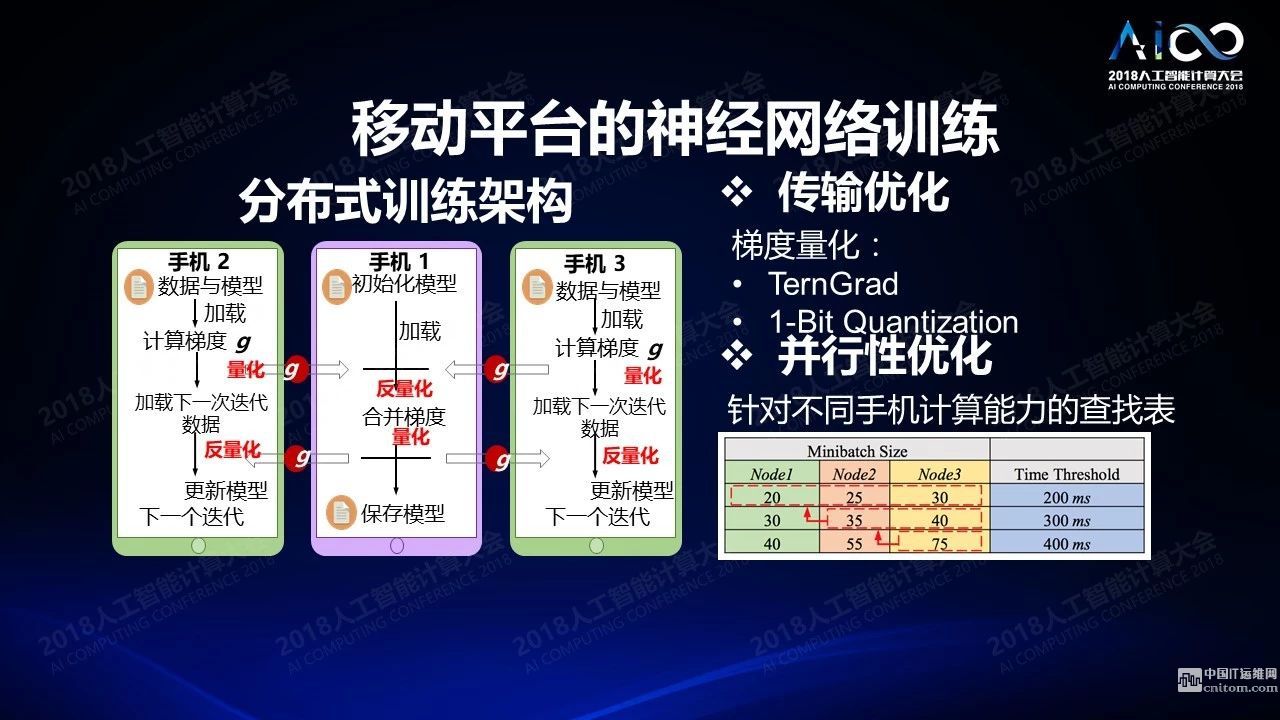
云和终端是不一样的,云端和终端的设计完全不同,云端需要对海量数据进行处理,要进行存储,要进行训练,要高并行高带宽,终端上首先要采集,然后做终端的推理,还要做一些简单的训练,还关心安全性、低能耗、低延时等等的处理。我们在很多年前开始做移动计算,我们最近开始转移到移动平台的神经网络的训练以及推理上来,去年有一篇文章拿了最佳论文奖,题目是分布式移动端的训练。它有点像移动端的参数服务器:我有一个手机对其他所有手机进行管理和同步,各个手机之间进行并行的训练,然后把低精度计算运用在上面。一些精确的分析会发现神经网络的各个层相对于资源的要求是完全不一样的。比如卷积层贡献了绝大多数的计算的开销,而全连接层贡献了绝大多数存储的开销。所以你在设计的过程中就需要考虑这样的差别。如果你在做稀疏化的时候,稀疏化之后可以对计算本身做一个聚类,这样聚类之后的比较复杂的比较密集的网络可以部署到同一个节点,减少节点之间相互传输的开销。

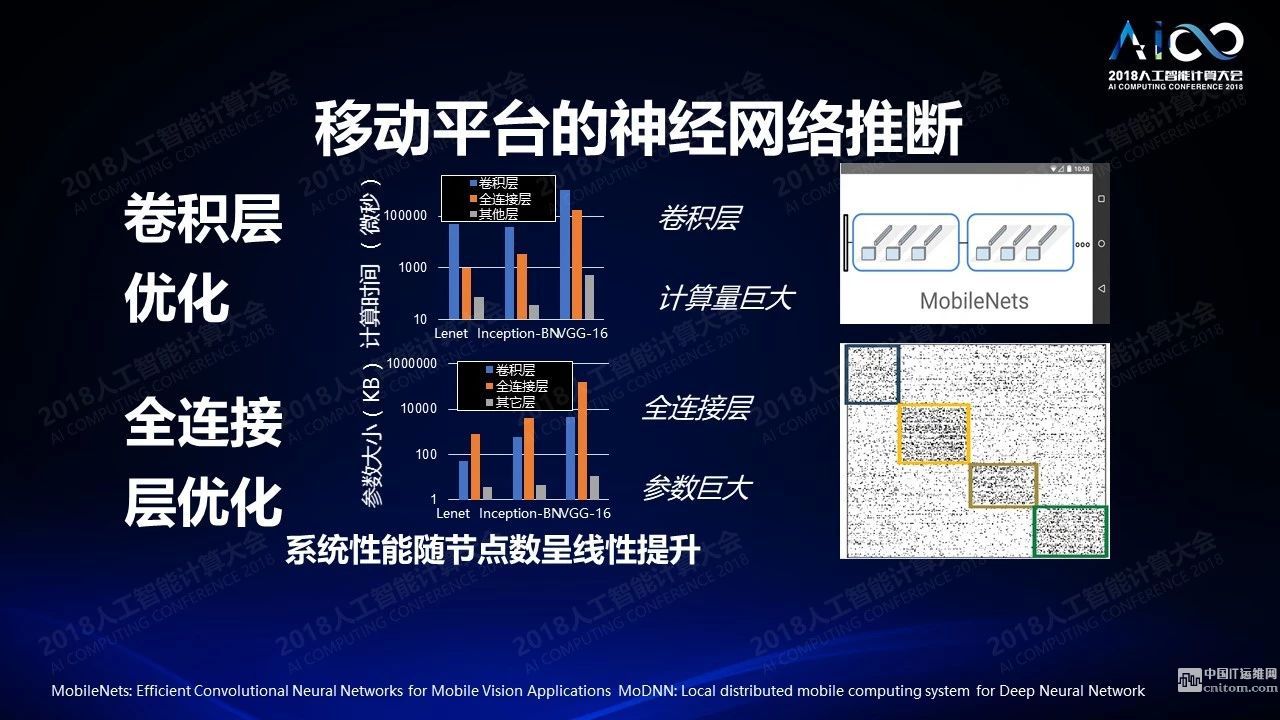
另外说尽管它是一个中心化的网络,我们也可以把它做成一个去中心化的网络或半去中心化的网络,来提高它的安全性,降低对于中心节点的应用。你还需要考虑在节点相互之间的传输的开销,因为我们知道对于移动网络来讲建立网络之间相互的通道是非常昂贵的。我们可以随着节点数目的增长基本达到线性的提升,这是不太容易做到的事情。
挑战4:芯片设计要求高,周期长,成本昂贵
这是一个芯片周期的图,从芯片规格设计芯片结构设计、RTL设计、物理半途设计、晶圆制造、晶圆测试封装,需要2到3年时间,正常情况下这段时间里软件会有一个非常快速的发展。下面这张表是如果你看到TPU生产设计的周期和Tensorflow的周期,两种不同的TPU版本之间Tensorflow已经更新了7到8个版本,这么长的周期能够支持在这个周期里新的软件版本的更新是非常具有挑战性的问题。
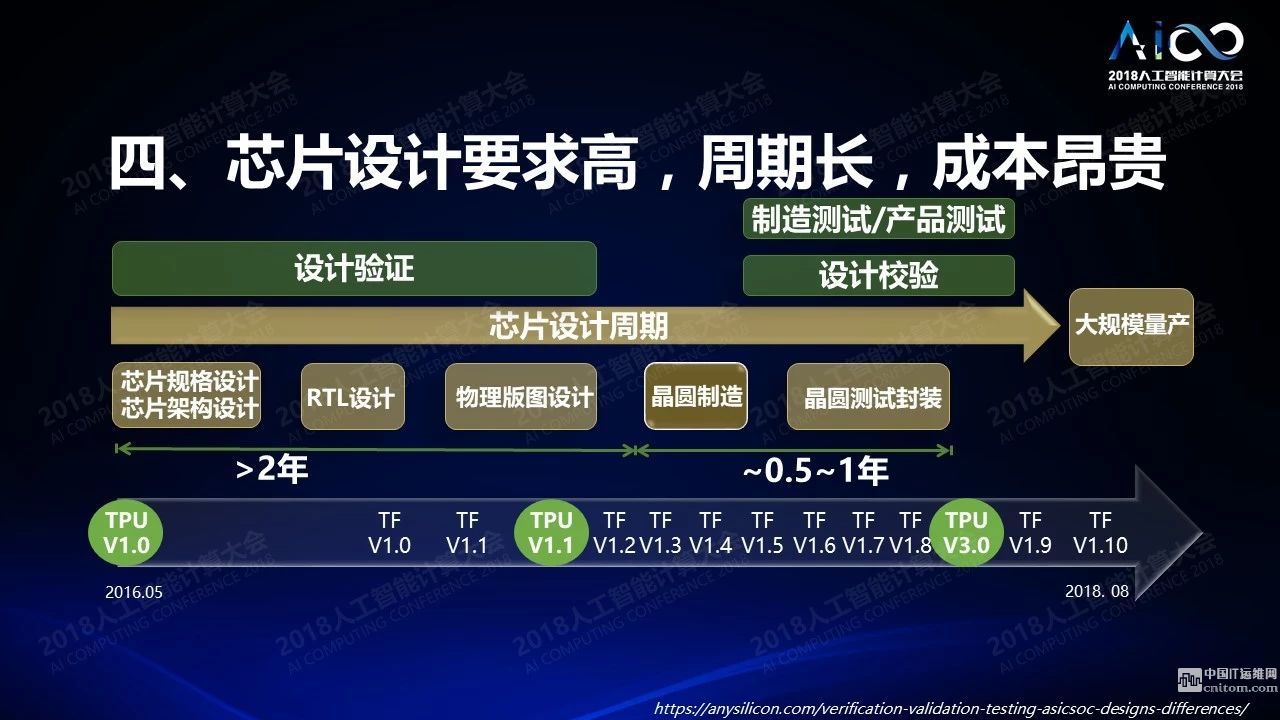
其中一个解决方案是可以通过AI本身去加速芯片的设计,最近我们在跟英伟达做一个合作,通过AI的设计提高版图的效率,我们把不同的AI的算法,像SVM和比较复杂的神经网络包括强化学习,做了一个对比。这是一个最近非常热门的话题,因为美国最近有一个项目,如果从最开始芯片定义到设计完成包括系统级封装的设计,希望是24小时无人值守,这是一件非常不容易的事情。对一个芯片,它的生命周期大概有三年时间,芯片从生产出来到产品消亡,三年里真正挣钱的时间是12-18个月,你怎么在12-18个月里降低成本提高利润率完成这个周期的迭代,AI技术可以做出大量的贡献。
挑战5:架构及工艺面临的挑战
最后一个问题是架构及工艺面临的挑战。这张图是摩尔定律的另一个表达形式:随着我们的工艺不断的提升,从90纳米到10纳米,每代逻辑门生产的成本到最后变得饱和。我们也许在速度上、功耗上会有提升,但单个逻辑生产的成本不会再有新的下降。这种情况下如果仍然用几千甚至上万个晶体管去做一个比较简单的深度学习的逻辑,那你会发现到最后在成本上是得不偿失的。英特尔一直在说我计划发布多少纳米的生产技术,实际上永远是在延后的,越往下做越贵越不容易。

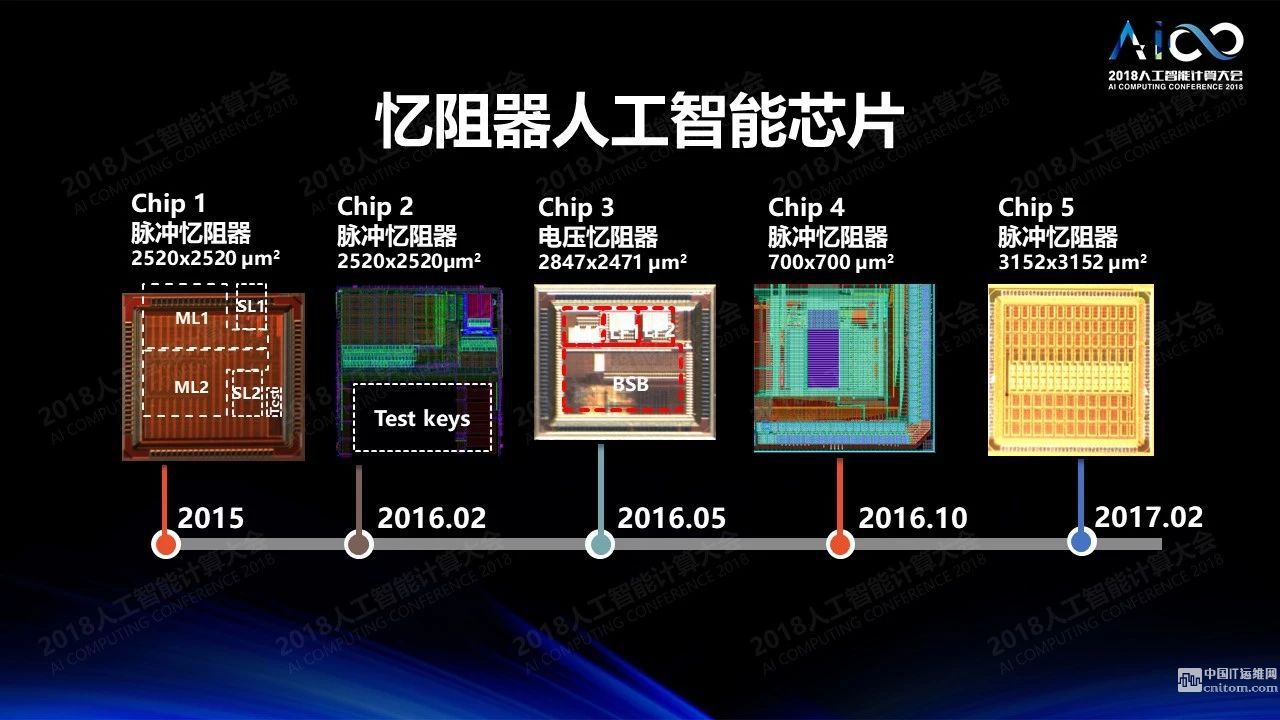
怎么解决这个问题?一个有趣的技术是忆阻器。这个北大的黄如老师、中科院的刘明老师他们也在做。这个器件有一些很有意思的特点,它的特性非常像人的神经网络里面的神经元,我们神经突触是连接两个神经元的。一个神经元产生一个信号之后这个信号就会通经神经突触到另一个神经元上去,神经突触本身会把信号放大,倍数是可控的。忆阻器的特点是他的电阻值可以变化。当你加了一个电压之后产生的电流本身的幅度是可调的,有点像将两个神经元连在一起的神经突触,整个过程其实是在做乘法。这个器件只有几个纳米那么大。通过这个器件可以产生一个交叉互联的结构,这种交叉互联的结构可以非常有效的把向量和矩阵相乘的形式加以变换,进行有效的计算,可以一下子把n×n×n的计算一次性全部算出来,非常有效。过去很多年里我们一直在做这方面的研究,从单个器件一直做到模型、计算的原理,最近我们开始做芯片,这个图上是其中的一些例子,用脉冲来表示数据,到电压忆阻器,一步步走过来。我去台积电访问,希望他们能支持我们这项研究。他们跟我讲放心,他们也在做这个工作,如果摩尔定律放缓的话下面我们怎么走只能看新的材料。
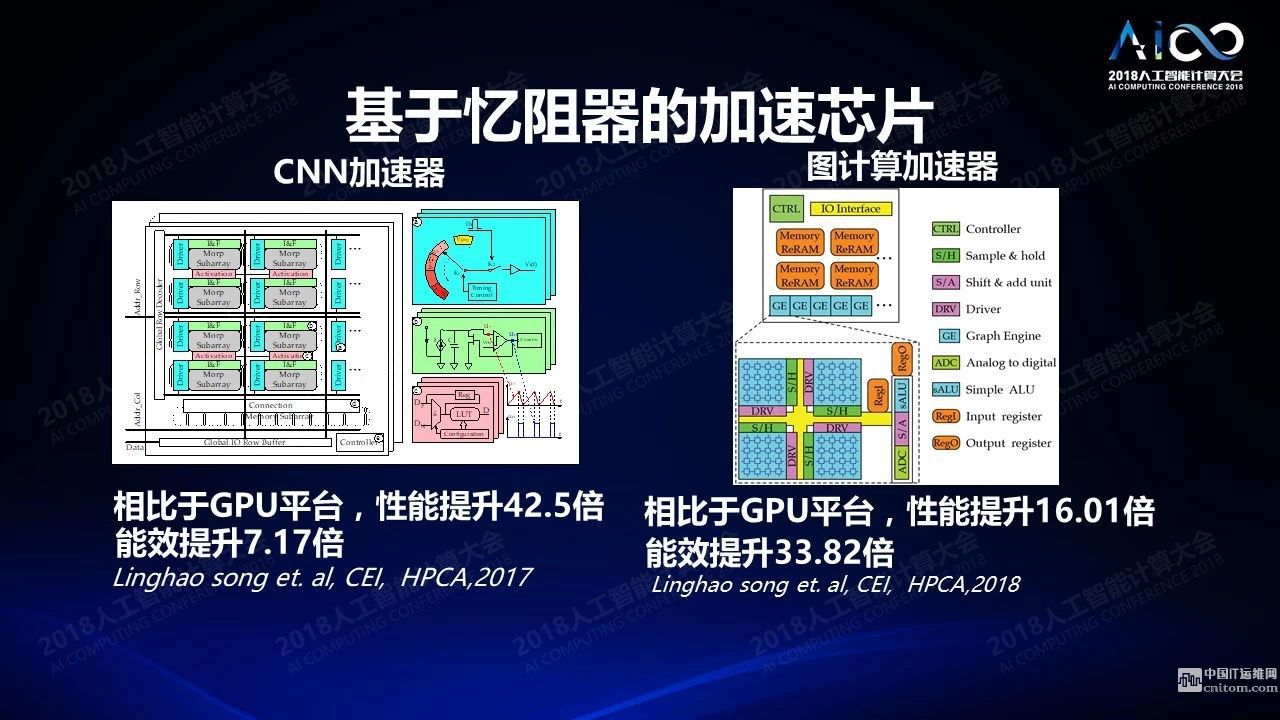
当我们有了基于忆阻器的加速芯片之后做的另外一件事情是怎么把它真的用起来,把它做到新的计算架构里面去。比如我可以把它以加速器的方式做到传统的流水线里面去,相比GPU的平台性能可以提高几十倍,能效提高5到10倍。神经网络只是图计算的一个特例,只是用某种图的形式把这些计算连接起来,所以在图计算上我们也可以做相应的处理,不光是做深度优先算法还可以做广度优先算法,我们都可以通过新型器件的方式加以计算,性能也有几十倍左右的提升。这在现在这是非常热门的领域,它的本质是模拟计算,不是简单的通过传统的科学计算的方式来完成计算,而是更有效的模拟神经计算。
我们总结一下我们想做的事情,我经常被问到一个问题,哪个平台哪个技术在未来有可能赢得这场战争,GPU公司还是基于新型器件的初创公司都希望知道答案,这意味着几百亿或几千亿的市场。为了回答这个问题我们总结了5个我们觉得比较重要的维度:AI硬件的特性、适应性,性能功效、可编程性和可扩展性。我们做了一个雷达图进行比较。无论是对于通用硬件平台还是对于可编程器件没有任何一个会在这五种特性里达到最优的结果,都是有一两个比较好或两三个比较好,但另外一个比较差。回答这个问题,如果你问我哪个能赢,我首先要问你你要告诉我你的业务场景、你的数据类型、你愿意花的成本和你需要的计算开销等等参数甚至技术本身的成熟度,然后我告诉你哪一种是最适合你的结果,这是我们觉得比较重要的一件事情,当然也包括类脑架构等比较新型的计算架构。

AI芯片变得如此重要,最近我们在美国自然科学资金委的思路下成立了一个新型可持续发展智能计算中心。我们觉得应用来源于具体的场景,帮助我们理解需要什么样的新的计算平台,需要什么样的技术,我们才能设计更多更好更有效的硬件来为这个目的服务。


